想一想有没有遇到下面的场景:
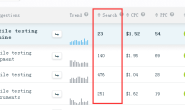
几个重点关键词好不容易优化到谷歌首页了,突然发现GA里多了一些国内IP,这些IP停留时间不短,跳出率也不高,但是绝对不会产生订单,并且偶尔可能还会有几个中文的注册或邮件,当然都是来测试的,上面这些还没什么问题,但是过段时间你会发现自己联系的独门外链和广告,竞争对手也上了,再一看他们的外链布局,要是不看时间不看网址,没准你还以为这就是几个月前自己网站的外链呢。

所以,当排名做上之后,屏蔽ahrefs、semrush、majestic、moz等外链(关键词)分析工具是非常有必要的,当竞争对手无法在这些分析工具获得我们网站信息的时候,相对来说,我们的排名安全了很多。
(当然,我相信很多人也是照搬曾经排在我们之前的竞争对手外链把排名做起来的,所以换位思考,这种无可厚非。)
如何屏蔽ahrefs、semrush、majestic等外链分析工具呢?其实很简单,只需要在robots文件里加一些语句就可以了。
因为这些工具也跟谷歌一样,是靠爬虫爬取互联网上各个网站的信息,这些工具的爬虫爬到了我们网站,工具里就能看到我们网站的信息,如果我们不允许这些工具的爬虫爬取,那自然就看不到了。
好在互联网上所有的爬虫都遵循robots规则,所以只要我们在robots文件里将需要禁止的爬虫列出来并禁止他们爬取我们的网站,这样基本就搞定了。
如果你不懂robots,可以查看这篇文章《详细robots.txt规则大全和禁止目录及指定页面收录》(简单详细且枯燥)
当你感觉差不多懂了,把下面的语句加到robots文件即可:
User-agent: Rogerbot
User-agent: Exabot
User-agent: MJ12bot
User-agent: Dotbot
User-agent: Gigabot
User-agent: AhrefsBot
User-agent: BlackWidow
User-agent: ChinaClaw
User-agent: Custo
User-agent: DISCo
User-agent: Download\ Demon
User-agent: eCatch
User-agent: EirGrabber
User-agent: EmailSiphon
User-agent: EmailWolf
User-agent: Express\ WebPictures
User-agent: ExtractorPro
User-agent: EyeNetIE
User-agent: FlashGet
User-agent: GetRight
User-agent: GetWeb!
User-agent: Go!Zilla
User-agent: Go-Ahead-Got-It
User-agent: GrabNet
User-agent: Grafula
User-agent: HMView
User-agent: HTTrack
User-agent: Image\ Stripper
User-agent: Image\ Sucker
User-agent: Indy\ Library
User-agent: InterGET
User-agent: Internet\ Ninja
User-agent: JetCar
User-agent: JOC\ Web\ Spider
User-agent: larbin
User-agent: LeechFTP
User-agent: Mass\ Downloader
User-agent: MIDown\ tool
User-agent: Mister\ PiX
User-agent: Navroad
User-agent: NearSite
User-agent: NetAnts
User-agent: NetSpider
User-agent: Net\ Vampire
User-agent: NetZIP
User-agent: Octopus
User-agent: Offline\ Explorer
User-agent: Offline\ Navigator
User-agent: PageGrabber
User-agent: Papa\ Foto
User-agent: pavuk
User-agent: pcBrowser
User-agent: RealDownload
User-agent: ReGet
User-agent: SiteSnagger
User-agent: SmartDownload
User-agent: SuperBot
User-agent: SuperHTTP
User-agent: Surfbot
User-agent: tAkeOut
User-agent: Teleport\ Pro
User-agent: VoidEYE
User-agent: Web\ Image\ Collector
User-agent: Web\ Sucker
User-agent: WebAuto
User-agent: WebCopier
User-agent: WebFetch
User-agent: WebGo\ IS
User-agent: WebLeacher
User-agent: WebReaper
User-agent: WebSauger
User-agent: Website\ eXtractor
User-agent: Website\ Quester
User-agent: WebStripper
User-agent: WebWhacker
User-agent: WebZIP
User-agent: Wget
User-agent: Widow
User-agent: WWWOFFLE
User-agent: Xaldon\ WebSpider
User-agent: Zeus
Disallow: /
基本上很多常用分析工具的爬虫都屏蔽了。
当然,除了robots屏蔽之外,我们还可以通过.htaccess文件来屏蔽爬虫,具体的写法如下:
SetEnvIfNoCase User-Agent .*rogerbot.* bad_bot
SetEnvIfNoCase User-Agent .*exabot.* bad_bot
SetEnvIfNoCase User-Agent .*mj12bot.* bad_bot
SetEnvIfNoCase User-Agent .*dotbot.* bad_bot
SetEnvIfNoCase User-Agent .*gigabot.* bad_bot
SetEnvIfNoCase User-Agent .*ahrefsbot.* bad_bot
SetEnvIfNoCase User-Agent .*sitebot.* bad_bot
<Limit GET POST HEAD>
Order Allow,Deny
Allow from all
Deny from env=bad_bot
</Limit>
直接加到.htaccess文件即可。应该是只有Apache服务器支持.htaccess,如果是nighx服务器,可能需要转一下。
如果你实在不懂robots和.htaccess,没关系,随便去淘宝找个服务器运营店主,把要加的东西给他,最多几十块钱给你搞定。
(上述两种方法不一定可以完全屏蔽掉分析工具的爬虫,因为他们其实可以不遵循规则硬是爬取你的网站,所以你还可以通过服务器屏蔽这些分析工具的IP,这个操作性也有难点,这里就不展开了,因为一般情况下,robots和.htaccess就够了。)
当然除了屏蔽分析工具之外,其实屏蔽竞争对手访问也是有必要的,因为你不知道什么时候,竞争对手就看了你写的文章和布局的TDK,然后比你做的更好,并超过你。
如何屏蔽呢,通常这么几种方法,第一屏蔽中国IP,这种方法简单,但是一般没啥用,国内IP屏蔽了,翻墙不一样看吗?
第二种,屏蔽中文浏览器,浏览器语言是中文的一律不能访问,操作方式也比较简单,把下面一段代码加到网站所有页面头部就可以了:
<script type=”text/javascript”>
if (navigator.language)
var language = navigator.language;
else
var language = navigator.browserLanguage;
if(language.indexOf(‘zh’) > -1)document.location.href = ‘https://www.baidu.com’;
</script>
加上之后,如果访客使用的是中文浏览器,页面会直接跳转百度,修改后面地址,可以设置跳转到其他你想要的页面。
详细的可以看这篇文章《外贸建站屏蔽中文浏览器或ip》
除了这两种方法,你还可以屏蔽中文操作系统,这样基本就杜绝一切国内竞争对手了,具体代码参考《外贸网站屏蔽中文操作系统代码》(是否正确有效,未检查)。
(还是那个问题,你如果觉得不懂代码,不懂服务器,没关系,淘宝找人,给他代码或者让他自己找,帮你搞定,也就几十块钱。)
最后,你也可以参考这篇文章《外贸英文建站:如何禁止国内同行访问你的英文网站?》
这样,当你通过上述步骤之后,网站基本就可以比较好的封闭起来了,竞争对手想搞你的套路,那基本是很难了。